
🗓️ 7주차: 5월 18일 ~ 5월 22일
멀티캠퍼스 부트캠프 7주차 요약✍️
[ 5/18 ] 머신러닝: XGBoost, PCA, K-Means, t-SNE
[ 5/19 ] 머신러닝: DBSCAN
[ 5/20 ] 딥러닝: 이론 학습. 본문에서는 생략
[ 5/21 ] 딥러닝: torch
[ 5/22 ] 딥러닝: RNN
5월 18일👩🏻💻
오늘의 소감: 월요일 힘들지만... 힘들다 응.. 힘들어. ㅋㅋㅋㅋㅋ정신줄 붙잡자🥹
💻 XGBoost
부스팅의 대표적인 모델로, 빠른 속도, 높은 성능, 과적합 제어 기능을 제고아는 트리 기반 앙상블 모델
body dataset 활용
from xgboost import XGBClassifier, XGBRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report, mean_squared_error, r2_score
import pandas as pd
import numpy as np
body = pd.read_csv('../data/bodyPerformance.csv')
body.head(3)
# 성별/등급을 수치형 데이터로 변환
body['gender'] = np.where(
body['gender'] == 'M', 0, 1
)
body['class'] = body['class'].map({'A': 0, 'B': 1, 'C': 2, 'D': 3})
body.head(3)
X = body.drop('class', axis = 1)
y = body['class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, \
random_state = 42, stratify = y)# XGBoost 분류 모델을 생성 (다중 분류 모델 → softmax 기반)
clf = XGBClassifier(
n_estimators = 1000,
learning_rate = 0.05,
objective = 'multi:softprob',
eval_metric = 'mlogloss',
max_depth = 5,
min_child_weight = 2,
subsample = 0.8,
colsample_bytree = 0.8,
early_stopping_rounds = 50,
random_state = 42,
tree_method = 'hist'
)
clf.fit(X_train, y_train, eval_set = [(X_test, y_test)], verbose = 50)
print("Best Iteration: ", clf.best_iteration)
print("Best Score: ", clf.best_score)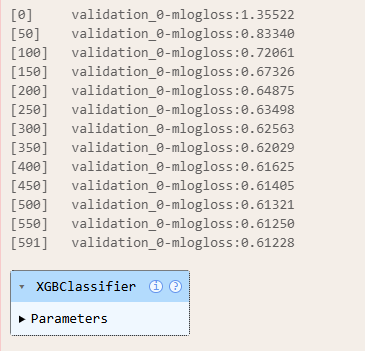

clf_pred = clf.predict(X_test)
print(confusion_matrix(y_test, clf_pred))
print()
print(classification_report(y_test, clf_pred))
hyper parameter들을 조정해주며 성능을 더욱 향상시킬 수 있다.
💻 PCA
차원 축소 기법으로, 고차원 데이터를 상관관계가 없는 새로운 축으로 변환, 이때 데이터의 분산을 최대한 보존하면서 축소한다.
iris dataset 활용
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split, GridSearchCV, StratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC, SVR
from sklearn.metrics import classification_report, r2_score
iris = pd.read_csv('../csv/iris.csv')
iris.head()
X = iris.drop('species', axis = 1)
y = iris['species']
pca = PCA()
X_pca = pca.fit_transform(X, y)X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.2, random_state = 42, stratify = y
)
# KFold 생성
cv = StratifiedKFold(
n_splits = 5, shuffle = True, random_state = 42
)
# Pipeline 생성: Scaler → PCA → SVC
pipe = Pipeline(
[
('scaler', StandardScaler()),
('pca', PCA(random_state = 42)),
('svc', SVC(random_state = 42, probability = True))
]
)
# 최적의 parameter를 찾기 위한 parameter의 조합
params = {
'pca__n_components' : [None, 2, 3],
'svc__C' : [0.1, 1, 10],
'svc__gamma': ['scale', 'auto'],
'svc__kernel' : ['linear', 'rbf']
}
# GridSearchCV 객체를 생성
grid = GridSearchCV(
estimator = pipe,
param_grid = params,
scoring = 'accuracy',
cv = cv,
n_jobs = -1,
verbose = 1,
refit = True
)grid.fit(X_train, y_train)
print('Best estimator: ', grid.best_estimator_)
print('Best Parameter: ', grid.best_params_)
print(classification_report(
y_test, grid.predict(X_test)
))
💻 K-means
k개의 그룹으로 자동 분류하는 비지도 학습 알고리즘으로,
그룹의 중심점을 반복적으로 계산하여 서로 가까운 데이터끼리 묶어 군집을 형성한다.
iris dataset 활용
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score, adjusted_rand_score
iris = pd.read_csv('../csv/iris.csv')X = iris.drop('species', axis = 1)
y = iris['species']
X_std = StandardScaler().fit_transform(X)# Kmeans 객체 생성
model = KMeans(
n_clusters = 3,
random_state = 42,
n_init = 10
)
model.fit(X_std)
labels = model.predict(X_std)# 검증 지표 (군집이 얼마나 잘 되었는가?)
inertia = model.inertia_
silhouette = silhouette_score(X_std, labels)
chs = calinski_harabasz_score(X_std, labels)
dbs = davies_bouldin_score(X_std, labels)
# 실제 라벨과의 계산
ari = adjusted_rand_score(y, labels)
print('inertia: ', round(inertia, 3))
print('silhouette: ', round(silhouette, 3))
print('calinski: ', round(chs, 3))
print('davies: ', round(dbs, 3))
print('ARI: ', round(ari, 3))
inertia: 139.82
silhouette: 0.46
calinski: 241.904
davies: 0.834
ARI: 0.62
이때 inertia_, davies_Bouldin_score은 작을수록 좋고, calinski_Harabasz_score은 높을수록 좋으며,
silhouette_score, adjusted_rand_score은 1에 가까울수록 좋다.
# 군집의 상황을 2차원 그래프로 시각화 → 차원 축소
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_std)
# pca를 이용해서, 중심점을 2차원으로 축소
center_pca = pca.transform(model.cluster_centers_)
plt.figure(figsize = (12, 8))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c = labels, cmap = 'viridis', s = 40, alpha = 0.7)
plt.scatter(center_pca[:, 0], center_pca[:, 1], c = 'black', s = 100, marker = 'X', label='center')
plt.legend()
plt.show()
💻 t-SNE
비선형 차원 축소 기법으로, 고차원 데이터의 국소 구조를 보존하면서 2차원 또는 3차원 시각화를 하기 위해 사용한다.
고차원 데이터의 경우에는 거리 기반 유사도를 사용하며, 저차원의 경우에는 t-분포를 이용해 확률적으로 비슷하게 재현한다.
digits dataset 활용
digits dataset은 숫자를 나타내는데 필요한 데이터를 담은 dataset이다.
해당 dataset에 포함된 image column을 활용하여 시각화를 하면 다음과 같은 이미지가 도출된다.
각 데이터가 0 ~ 9 중 어디에 속하는지 시각화를 수행하는 작업을 수행할 것이다.

import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_digits
from sklearn.preprocessing import StandardScaler
from sklearn.manifold import TSNE
digits = load_digits()
pd.DataFrame(digits.data)
column이 64개다 = 64차원이다.
tsne = TSNE(
n_components=2,
perplexity=40,
random_state=42,
n_jobs=-1
)
X = StandardScaler().fit_transform(digits['data'])
y = digits['target']
X_tsne = tsne.fit_transform(X)
print(X.shape) # (1797, 64)
print(X_tsne.shape) # (1797, 2)기존 64차원에서 2차원으로 줄어든 모습을 볼 수 있다.
plt.figure(figsize=(16, 10))
sc = plt.scatter(
X_tsne[:, 0], X_tsne[:, 1], c = y, cmap = 'cool', s = 40
)
plt.legend(*sc.legend_elements(), title='Digits')
plt.show()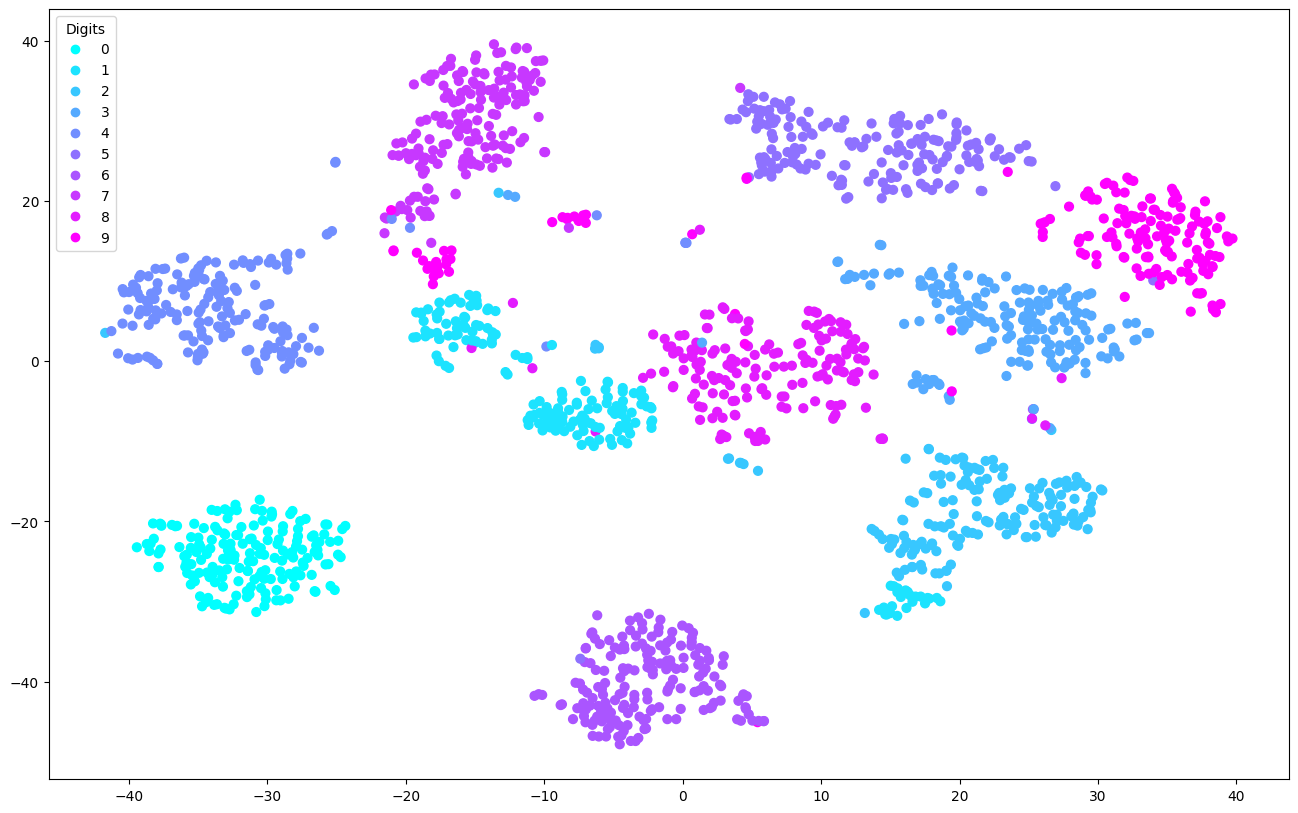
각 target 별로 데이터가 뭉쳐져 있는 모습을 확인할 수 있다.
5월 19일👩🏻💻
오늘의 소감: 대학교에서 진행했던 팀플에서 DBSCAN을 사용할 뻔한 적이 있었는데,
그때만 해도 관련 과정을 많이 듣지 않았던 때라 뭔지 몰라서 헤매었던 기억이 있다.
(배운 것 이외의 방법이 나오면 많이 쫄았었지...)
많은 방법을 접하고 있는 지금을 새로이 도전하는 것을 두려워하지 않는 계기로도 발전시켜나갔으면 좋겠다.
💻 DBSCAN
밀도 기반의 클러스터링 알고리즘으로, 데이터의 밀도를 이용하여 군집을 생성한다.
body dataset 활용
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.cluster import DBSCAN
from sklearn.neighbors import NearestNeighbors
from sklearn.metrics import silhouette_score, adjusted_rand_score
from sklearn.decomposition import PCA
body = pd.read_csv('../data/bodyPerformance.csv')
늘 그랬듯 범주형 데이터를 수치로 변환하고, 독립/종속으로 분할
obj_cols = body.select_dtypes('object').columns
le = LabelEncoder()
for col in obj_cols:
body[col] = le.fit_transform(body[col])
X = body.drop(['class'], axis = 1)
y1 = body['class']
y2 = body['gender']
X_std = StandardScaler().fit_transform(X)
X 데이터에서 k번째 최근접 이웃의 거리를 계산
각각의 거리 데이터에서 10번째 이웃의 거리만 추출하여 kth_list에 저장
nbrs = NearestNeighbors(n_neighbors=10).fit(X_std)
distances, idxs = nbrs.kneighbors(X_std)
kth_list = np.sort(distances[:, -1])
plt.figure(figsize=(5, 5))
plt.plot(kth_list)
plt.grid(True)
plt.show()
값이 13,000 근처에서 확 꺾이는 것을 볼 수 있는데, 이 꺾인 뒤의 값들은 노이즈라고 생각할 수 있으며,
해당 부분의 y값을 eps로 잡아주면 된다.
diffs = np.diff(kth_list)
eps_ = np.where(diffs>0.05)[0]
print('급변하는 인덱스의 값: ', eps_)
print('대략적인 eps의 최적값: ', kth_list[eps_[0]])
# 급변하는 인덱스의 값: [13357 13370 13371 13374 13376 13378 13380 13382 13383 13384 13385 13386 13387 13388 13389 13390 13391]
# 대략적인 eps의 최적값: 3.051458810772378
DBSCAN
db = DBSCAN(
eps = 1.7,
min_samples = 10,
n_jobs = -1
)
labels = db.fit_predict(X_std)set(labels)
db = DBSCAN(
eps = 1.7,
min_samples = 10,
n_jobs = -1
)
labels = db.fit_predict(X_std)
# 검증 지표
# 노이즈 제외하고 검증
flag = labels != -1
sil = silhouette_score(X_std[flag], labels[flag])
ari = adjusted_rand_score(y1, labels)
print(sil)
print(ari)
# 0.3466129480317822
# 0.0049927528548928055막상 eps를 3으로 지정하니까 군집이 하나만 생성되었기에, eps값을 1.7로 낮추어 분석을 진행하였다.
# PCA를 이용하여 2차원으로 차원 축소하고 그래프 시각화
pca = PCA(n_components=2, random_state=42)
X_pca = pca.fit_transform(X_std)
# 노이즈 / 비노이즈 부분을 다르게 표시
non_noise = labels != -1
# 비노이즈 산점도 그래프 표시
plt.scatter(X_pca[non_noise, 0], X_pca[non_noise, 1], \
c = labels[non_noise], cmap = 'cool', label = 'Cluster', alpha = 0.5)
# 노이즈 산점도 그래프 표시
plt.scatter(X_pca[~non_noise, 0], X_pca[~non_noise, 1], c = 'black', label = 'Noise', alpha = 0.3)
plt.legend()
plt.show()
5월 21일👩🏻💻
오늘의 소감: 학교에서는 Tensorflow로만 하다가 Torch를 하니까 좀 어색한 느낌이 있다...🥹
코드를 다시 살펴보며 꼼꼼히 복습해야겠다.
💻 Torch - 선형 모델
import torch
import torch.nn as nn
import torch.optim as optimtorch: tensor type으로 parsing하기 위함
nn: 기본 뼈대
optim: 기울기 변화를 주는 기능
독립, 종속변수 tensor로 생성
X = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
y = torch.tensor([[3.0], [5.0], [7.0], [9.0]])# 순전파 (모델 학습 → 예측)
class LinearReg(nn.Module):
def __init__(self):
super(LinearReg, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)클래스 생성
model = LinearReg()
손실함수, 옵티마이저 설정
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr = 0.01)모델 학습 (1번)
# 순전파 (생성된 모델을 호출하면 forward() 함수를 호출하도록 nn.Module에서 설정되어있음)
pred = model(X)
# LinearReg 클래스 안의 forward 함수를 호출하여 독립변수(x)를 인자값으로 사용한다.
# 손실 함수
loss = criterion(pred, y)
# 기울기 초기화
optimizer.zero_grad()
# 역전파 (자동 미분) → 데이터가 있는 쪽으로 방향을 제시한다
loss.backward()
# 가중치를 업데이트 (파라미터(모델) 수정)
optimizer.step()
# loss 값을 확인
print(loss)
# tensor(49.5290, grad_fn=<MseLossBackward0>)모델 평가
# DL 모델은 반복 학습이 기본 설정 → 학습 모드를 평가 모드로 전환
# eval(): 모델을 평가모드로 전환
# train(): 모델을 학습 모드로 전환
model.eval()
# 예측, 평가 (메모리의 사용량을 줄이기 위해서 가중치의 계산을 잠시 비활성화)
with torch.no_grad():
y_pred = model(X)
loss = criterion(y_pred, y)
print(y_pred)
print(loss)
# 반복 학습을 통해서 가중치와 편향을 변화시킨다.
epochs = 200
model.train()
for epoch in range(epochs):
# 순전파
pred = model(X)
# 손실 함수
loss = criterion(pred, y)
# 기울기 초기화
optimizer.zero_grad()
# 자동 미분(역전파) → 가중치의 방향을 제시
loss.backward()
# 가중치를 업데이트
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f"Epoch: [{epoch+1}, 200], Loss: {round(loss.item(), 6)}")
반복학습 후 모델 평가
model.eval()
with torch.no_grad():
y_pred = model(X)
loss = criterion(y_pred, y)
print(y_pred)
print(loss)
💻 Torch - 비선형 모델: 회귀
california dataset 활용
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
data = fetch_california_housing()
X = data['data']
y = data['target']
print(X.shape, y.shape)
# (20640, 8) (20640,)
# 1차원 데이터를 2차원으로 변경
y = y.reshape(-1, 1)
# 학습, 평가 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.2, random_state = 42
)
# Tensor 형태로 변환
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32)# 비선형 모델 생성 (선형 모델 → 활성화 함수 → 선형 모델)
class Reg2(nn.Module):
def __init__ (self, _dim):
super(Reg2, self).__init__()
# 다중 퍼셉트론 안에 선형 모델 → 활성화 함수 → 선형 모델
self.model = nn.Sequential(
# 첫번째 레이어
nn.Linear(_dim, _dim),
# 비선형 구조 파악용 활성화 함수
nn.ReLU(),
nn.Linear(_dim, 1)
)
def forward(self, x):
return self.model(x)model3 = Reg2(n_feature)
criterion3 = nn.MSELoss()
optimizer3 = optim.SGD(model3.parameters(), lr = 0.01)# 반복 학습
model3.train()
for epoch in range(300):
n = epoch + 1
pred3 = model3(X_train_sc)
loss3 = criterion3(pred3, y_train_tensor)
optimizer3.zero_grad()
loss3.backward()
optimizer3.step()
if n % 30 == 0:
print(f"Epoch [{n} / 300], Loss: {round(loss3.item(), 6)}")
model3.eval()
with torch.no_grad():
pred3 = model3(X_test_sc)
loss3 = criterion3(pred3, y_test_tensor)
for i in range(10):
print(f"실제 데이터: {y_test[i]}, 예측 데이터: {pred3[i].item()}")
💻 Torch - 비선형 모델: 분류
iris dataset 활용
import pandas as pd
from sklearn.metrics import accuracy_score, classification_report
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv('../csv/iris.csv')X = df.drop('species', axis = 1)
y = df['species']
le = LabelEncoder()
y = le.fit_transform(y)
y
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.2, random_state = 42, stratify = y
)
# Scaling
scaler = StandardScaler()
X_train_sc = scaler.fit_transform(X_train)
X_test_sc = scaler.transform(X_test)
# Tensor 형태로 변환
X_train_tensor = torch.tensor(X_train_sc, dtype = torch.float32)
X_test_tensor = torch.tensor(X_test_sc, dtype = torch.float32)
y_train_tensor = torch.tensor(y_train, dtype = torch.long)
y_test_tensor = torch.tensor(y_test, dtype = torch.long)
# 분류의 경우에는 종속변수를 long 타입으로 잡는다.class clf(nn.Module):
def __init__(self, _dim):
super(clf, self).__init__()
self.model = nn.Linear(_dim, 3)
def forward(self, x):
return self.model(x)
clf_model = clf(X.shape[1])
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(clf_model.parameters(), lr = 0.01)
pred = clf_model(X_train_tensor)
predclf_model.train()
for epoch in range(300):
pred = clf_model(X_train_tensor)
loss = criterion(pred, y_train_tensor)
optimizer.zero_grad() # 기울기 초기화
loss.backward() # 자동 미분
optimizer.step() # 기울기 업데이트
n = epoch + 1
if n % 30 == 0:
print(f'Epoch: [{n} / 300], Loss: {round(loss.item(), 6)}')
clf_model.eval()
with torch.no_grad():
pred = clf_model(X_test_tensor)
_, pred_idx = torch.max(pred, 1)
acc = accuracy_score(y_test, pred_idx)
print('정확도: ', round(acc, 4))
print(classification_report(y_test, pred_idx))
5월 22일👩🏻💻
오늘의 소감: 처음 보는 라이브러리는 역시 어려워🫨
💻 RNN
insurance dataset 활용
라이브러리, 데이터 로드
import math
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt데이터 생성, 전처리
np.random.seed(42)
torch.manual_seed(42)
# 노이즈를 포함한 연속성을 가진 sin 곡선 생성
x = torch.arange(3000).float()
y = torch.sin(2 * math.pi * 0.02 * x) + 0.05 * torch.randn(3000)
# train test split
train_size = int(0.8 * len(x))
print(train_size) # 2400
X_train = y[:train_size]
X_test = y[train_size:]
scaler = StandardScaler()
X_train_sc = scaler.fit_transform(X_train.reshape(-1, 1))
X_test_sc = scaler.transform(X_test.reshape(-1, 1))
# reshape를 통해 2차원 array의 형태로 변환
X_train_tensor = torch.tensor(X_train_sc, dtype = torch.float32)
X_test_tensor = torch.tensor(X_test_sc, dtype=torch.float32)
X_train_tensor.shape # torch.Size([2400, 1])
# Tensor Data를 배치가 존재하는 3차원 데이터로 변환
X_train_tensor = X_train_tensor.unsqueeze(0)
X_test_tensor = X_test_tensor.unsqueeze(0)
X_train_tensor.shape # torch.Size([1, 2400, 1])DataLoader
Pytorch에서 Dataset들을 batch 단위로 꺼내주는 반복자
반복 학습 루트에 맞는 형태의 데이터셋을 공급해주는 역할
# Custom Dataset 클래스 정의
class WindowDataset(Dataset):
def __init__(self, _data, _window):
# _data: 시계열 데이터
# _window : 구간 설정
self.data = _data
self.window = _window
# 유효 샘플의 개수 계산
# 입력 데이터: 전체 길이 - window 크기
self.n = len(self.data) - self.window
# __len__ 메서드: 데이터셋의 크기를 반환
# __getitem__ 메서드: 인덱스에 해당하는 샘플을 반환
# 특수 메서드: DataLoader가 데이터셋에서 데이터를 불러올 때 자동으로 호출
def __len__(self):
return self.n
def __getitem__(self, idx):
# DataLoader 실제로 입력된 데이터들을 슬라이스해서 가지고 가는 함수
x = self.data[ idx : idx + self.window ]
y = self.data[ idx + self.window ]
return x, yDataLoader 활용 데이터 분할
window = 10
train_ds = WindowDataset(X_train_tensor.squeeze(0), window)
test_ds = WindowDataset(X_test_tensor.squeeze(0), window)
batch_size = 10
x_list = []
y_list = []
for i in range(len(train_ds)):
if i == 10:
break
x, y = train_ds[i]
x_list.append(x)
y_list.append(y)
train_dl = DataLoader(
train_ds,
batch_size = 64,
drop_last=True,
shuffle=True
)
test_dl = DataLoader(
test_ds,
batch_size=64,
drop_last=True,
shuffle=False
)반복 학습
train_loss_list = []
test_loss_list = []
for epoch in range(20):
model.train()
running = 0.0
n_seen = 0
for x, y in train_dl:
x = x.float()
y = y.float()
# RNN 모델에 입력(x)을 넣어서 예측값(yhat)을 얻는다.
yhat = model(x)
loss = criterion(yhat, y)
optimizer.zero_grad()
loss.backward()
# 미분값 폭주 방지
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
running += loss.item() * x.size(0)
n_seen += x.size(0)
train_loss = running / max(1, n_seen)
train_loss_list.append(train_loss)
print(f'Epoch {epoch+1}, Train Loss: {round(train_loss, 8)}')
모델 평가
model.eval()
preds = []
trues = []
with torch.no_grad():
for x, y in test_dl:
x = x.float()
y = y.float()
pred = model(x)
preds.append(pred)
trues.append(y)
preds = torch.cat(preds, 0).squeeze(-1).numpy()
trues = torch.cat(trues, 0).squeeze(-1).numpy()시각화
plt.figure(figsize=(20, 13))
plt.plot(preds[:1000], label='Predicted')
plt.plot(trues[:1000], label = 'True')
plt.legend()
plt.grid()
plt.show()
7주차 소감
잘 버텨오다가 DataLoader에서 조금 무너졌다... 그래 여기까지가 내 배경지식이구나...🫠
참고도서를 읽어서 해당 부분 제대로 복습하고 다음 주 부분 들어가야겠다...!🥹
'멀티캠퍼스부트캠프' 카테고리의 다른 글
| 6주차 Note: 머신러닝 (0) | 2026.05.16 |
|---|---|
| 5주차 Note: 머신러닝 (1) | 2026.05.08 |
| 4주차 Note: 데이터 시각화 (0) | 2026.05.01 |
| 3주차 Note: 데이터 수집 (0) | 2026.04.26 |
| 2주차 Note: 프로그래밍 기초, 데이터 수집 (0) | 2026.04.26 |